Continuous Delivery for Machine Learning was written by ThoughtWorks employees Danilo Sato, Arif Wider and Christoph Windheuser. I copy-pasted much of this content, so please go straight to the source for any and all attributions of the ideas summarized below.
- Definition: Continuous Delivery for Machine Learning (CD4ML) is a software engineering approach in which a cross-functional team produces machine learning applications based on code, data, and models in small and safe increments that can be reproduced and reliably released at any time, in short adaptation cycles.
- Examples of reasons to make a change to part of a ML app
- Data: schema; sampling over time; volume
- Model: algorithims; more training; experiments
- Code: business needs; bug fixes; configuration
- Technical Components of CD4ML
- Discoverable and Accessible Data
- Definition: Data Pipeline is the process that takes input data through a series of transformation stages, producing data as output. For the purposes of CD4ML, we treat a data pipeline as an artifact, which can be version controlled, tested, and deployed to a target execution environment.
- How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh
- Reproducible Model Training
- Definition: The Machine Learning Pipeline” (aka, “model training pipeline”), is the process that takes data and code as input, and produces a trained ML model as the output. This process usually involves data cleaning and pre-processing, feature engineering, model and algorithm selection, model optimization and evaluation.
- If the ML pipeline is treated as the final automated implementation of the chosen model training process, then this would not be measured in the “time to model deployment” chart in the recent Algorithmia report.
- DVC: version control for data and machine learning projects
- Model Serving
- Approaches
- Embedded model: treat the model artifact as a dependency that is built and packaged within the consuming application
- Model deployed as a separate service: model is wrapped in a service that can be deployed independently of the consuming applications.
- Model published as data: in this approach, the model is also treated and published independently, but the consuming application will ingest it as data at runtime.
- MLflow: “Projects” is a packaging format
- Approaches
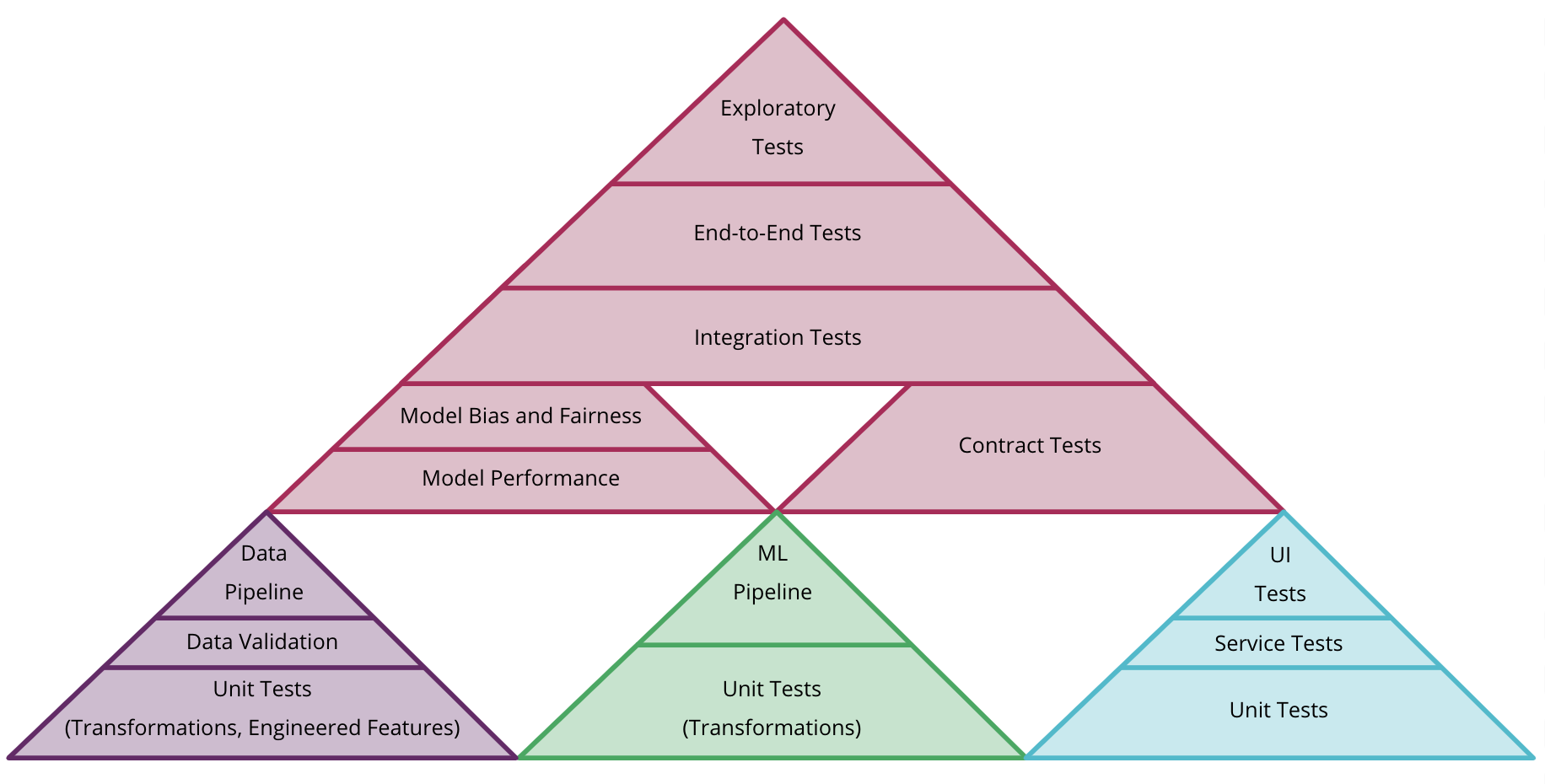
- Testing and Quality in Machine Learning
- Automated test can validate:
- Data
- Component integration
- Model quality
- Model bias and fairness
- Automated test can validate:
- Discoverable and Accessible Data
-
- Experiments Tracking
- Model Deployment
- Continuous Delivery Orchestration